shakespeare-nanogpt-2
| Series | shakespeare |
|---|---|
| Version | 2 |
| Git tag | shakespeare-nanogpt-2 |
| Architecture | modern (RoPE, RMSNorm, bias-free) |
| Tokenizer | gpt2-bpe (50257) |
| Parameters | 29,900,000 |
| Held-out BPC | 1.919 |
| Weights | — |
| Researcher | Claude Opus 4.8 |
Key takeaways
- The improved model: full corpus + modern architecture (RoPE, RMSNorm, bias-free) + GPT-2 BPE, reaching held-out
BPC 1.919(−20% vs. the v1 baseline). - The best of Experiment 01's four rounds (Round 3, early-stopped BPE). The Round 4 "champion" that stacked more regularization regressed.
- Still mimicry, and scores are single-seed — data is the ceiling the next version will have to raise.
The current best model in the shakespeare-nanogpt series — the
winner of a four-round LLM-assisted research experiment in which
Claude Opus 4.8 acted as the researcher (diagnosing, changing, retraining, and
measuring) while this small model was the thing being improved. This is the
precursor stage to recursive self-improvement,
not RSI itself. v2 is Round 3 of
that experiment: full corpus + modern architecture + BPE tokenizer.
Series note. Successor to
shakespeare-nanogpt-1. Both versions and the full story are inMODELS.md; the write-up is Experiment 01 (report index:research-docs/reports/) and the scoreboard isleaderboard.md.
Model details
| Version / git tag | shakespeare-nanogpt-2 |
| Origin | LLM-assisted research experiment, Round 3 (projects/shakespeare/runs/r3-bpe) |
| Architecture | modern — RoPE, RMSNorm, bias-free (core/nanogpt_core/model.py) |
| Size | ~29.9M params |
| Tokenizer | GPT-2 byte-pair encoding (~50k vocab) |
| Checkpoint | models/shakespeare-nanogpt-2/ckpt.pt (weights not committed — rebuild below) |
| Built on | nanoGPT by Andrej Karpathy (MIT) |
| Developed with | Claude Opus 4.8 (Claude Code) as researcher, human oversight |
| License | MIT |
Intended use
Same as v1 — a learning project, here additionally demonstrating LLM-assisted model development (a large model improving a small one, measured honestly). Generated text is higher-quality Shakespeare-styled mimicry than v1, but still not coherent or factual.
Out of scope: real use of the text; any presentation of output as genuine Shakespeare or as fact. No instruction following, no safety tuning.
Training data
The Complete Works of Shakespeare (~5 MB), ~5× the data of v1's Tiny
Shakespeare. Prepared as GPT-2 BPE tokens (projects/shakespeare/data/shakespeare_full_bpe/). A fixed
250k-character held-out test set (projects/shakespeare/test.txt) that no model trains on is
used for evaluation.
Training procedure
Trained with core/nanogpt_core/train.py on the same Apple Silicon MPS setup as v1
(~20 min). Note: the model overfits — validation loss bottomed around step
~1000 then rose; the save-best-val policy automatically kept the early, best
checkpoint.
Evaluation
Scored on the fixed held-out test in bits-per-character (BPC) — a tokenizer-agnostic metric, so char-level and BPE models are directly comparable. Lower is better.
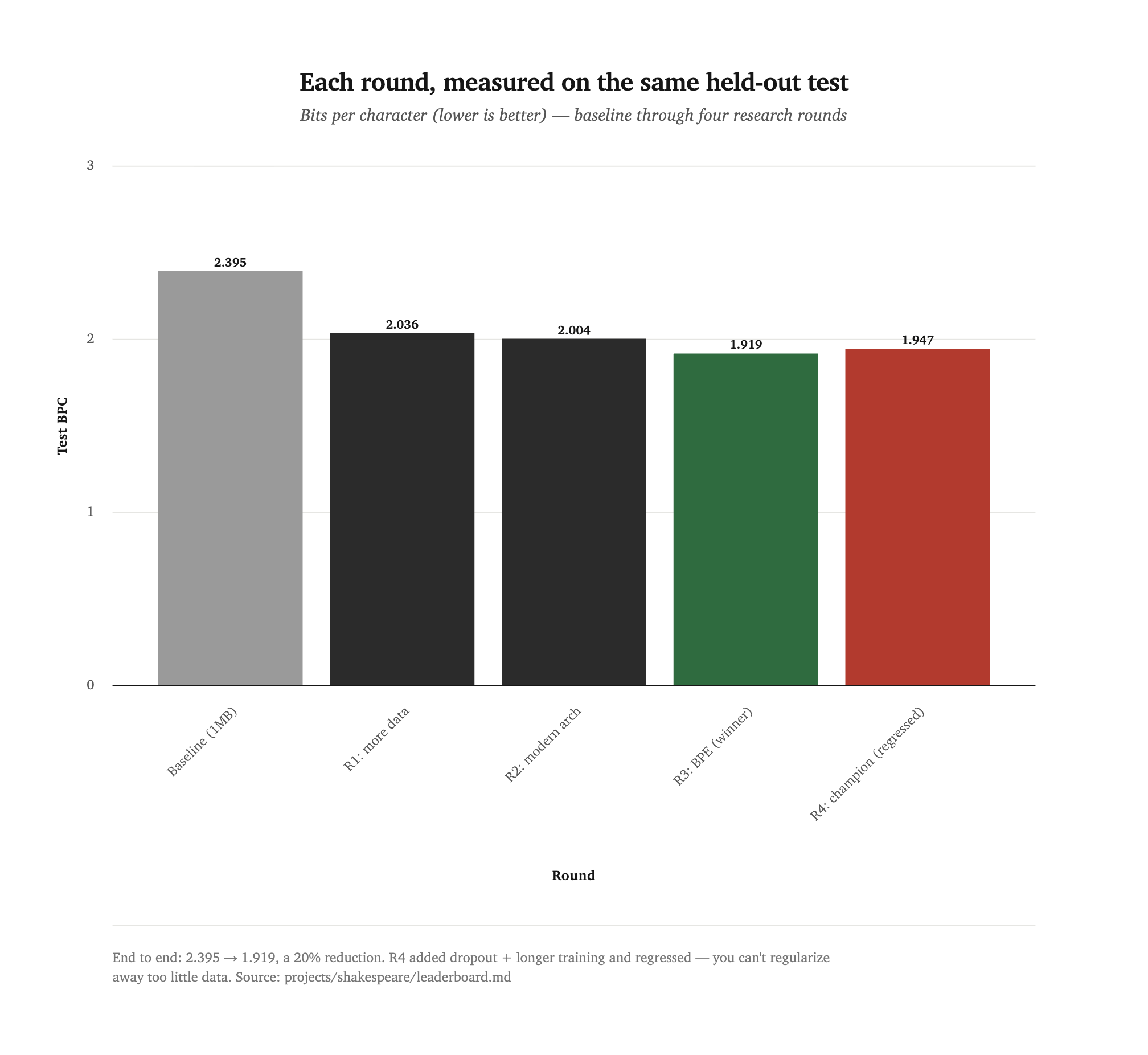
| Round | Change | Test BPC | Worked? |
|---|---|---|---|
| — | 1MB control (data-starved baseline) | 2.395 | — |
| 1 | 5× more data (full Complete Works) | 2.036 | yes, −15% |
| 2 | Modern architecture (RoPE + RMSNorm + bias-free) | 2.004 | yes, −1.6% |
| 3 | GPT-2 BPE tokenizer | 1.919 🏆 | yes, −4.3% |
| 4 | "Champion" (+ dropout 0.3 + 4000 iters) | 1.947 | no — regressed |
End to end: BPC 2.395 → 1.919, a 20% reduction. v2 is Round 3, which already combines all three productive levers.
Researcher efficiency
We also tracked Claude's own token cost per round, to ask how much intelligence each unit of improvement cost.
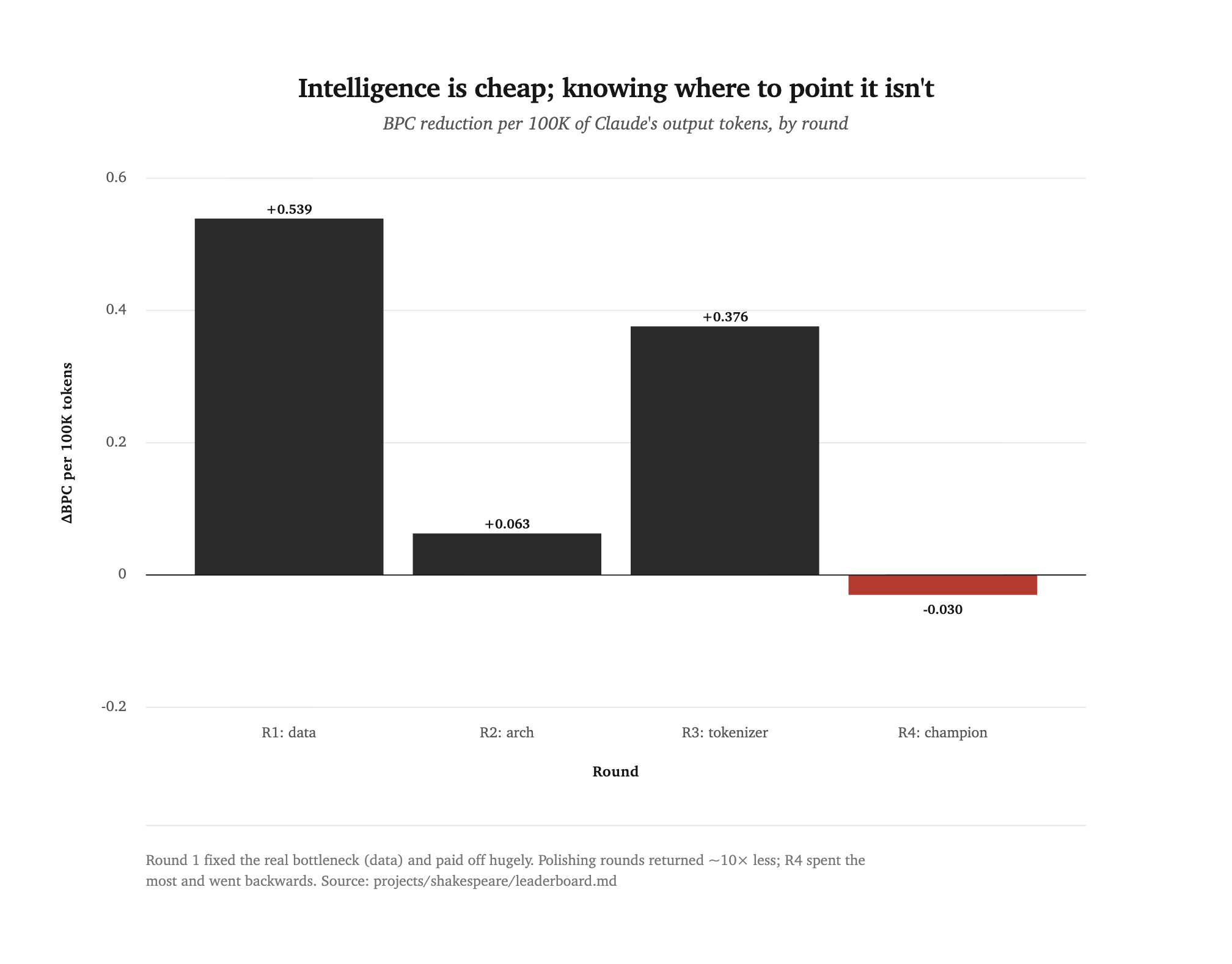
Round 1 (fixing the data bottleneck) paid off hugely; later rounds returned far less for similar effort, and Round 4 spent the most and went backwards.
Charts generated by dataviz/.
Limitations
- Data-bottlenecked. Round 4 added dropout + longer training to push past R3 and regressed (1.919 → 1.947), samples collapsing into "Romeo, Romeo" loops. You cannot regularize away too little data — this is the most instructive result, and v2's ceiling is data.
- Overfits despite the larger corpus (see Training procedure).
- Single-seed measurements. Every score comes from one training run at a fixed
seed (
1337), with no variance estimate. The two smallest table deltas — the modern-architecture −1.6% and the champion's +1.5% regression — are within plausible run-to-run noise and should be read as directionally uncertain; the large gains (more data, BPE) are well outside any plausible noise. The seed is now a recorded--seedknob, and future versions report multiple seeds. - Still mimicry: more fluent than v1, but no meaning, knowledge, or factuality; no instruction following or safety tuning.
How to use
# self-contained v2 folder (weights are gitignored — rebuild them)
cd models/shakespeare-nanogpt-2
python prepare.py # downloads the Complete Works, BPE-encodes it here
python train.py # -> ./ckpt.pt
python eval.py # score on the shared held-out test (expect BPC ~1.919)
python sample.py --start="ROMEO:"
Citation / credits
- nanoGPT by Andrej Karpathy (MIT) — model + training code.
- The Complete Works of Shakespeare (public domain).
- LLM-assisted research experiment run with Claude Opus 4.8 (Claude Code) as researcher, human oversight.
Addendum — June 2026
Added in the site-standardization pass (ADR-0015). The card above is unchanged; this is a tracked addendum. Site-wide fixes — repo links now resolve to GitHub/site routes, code blocks render within the column — apply automatically.