shakespeare-nanogpt-1
| Series | shakespeare |
|---|---|
| Version | 1 |
| Git tag | shakespeare-nanogpt-1 |
| Architecture | base (LayerNorm, learned position embeddings, biases) |
| Tokenizer | char (65) |
| Parameters | 10,700,000 |
| Held-out BPC | 2.395 |
| Weights | — |
| Researcher | Claude Opus 4.8 |
Key takeaways
- The original baseline: a ~10.7M-param char-level GPT on Tiny Shakespeare (validation loss 1.46).
- This is the controlled, data-starved baseline (held-out
BPC 2.395) that the LLM-assisted experiment set out to improve on. - Stylistic mimicry only — locally plausible, globally nonsense; it overfits, the regime later versions fix with more data.
The original baseline: a character-level GPT trained from scratch on Tiny
Shakespeare. First model in the shakespeare-nanogpt series.
Prompt it with a few characters and it continues them in convincingly-styled
(but semantically nonsensical) Early Modern English, one character at a time.
Series note. This is one checkpoint in a living, versioned series refined over time.
shakespeare-nanogpt-2is the successor; see its card andMODELS.md.
Model details
| Version / git tag | shakespeare-nanogpt-1 |
| Architecture | original nanoGPT — Transformer decoder, LayerNorm, learned positional embeddings, biases |
| Size | 6 layers · 6 heads · 384 embedding dim · 256 context · ~10.7M params |
| Tokenizer | character-level, 65-char vocabulary (direct char↔int lookup, no BPE) |
| Checkpoint | models/shakespeare-nanogpt-1/ckpt.pt (weights not committed — rebuild below) |
| Built on | nanoGPT by Andrej Karpathy (MIT), vendored unchanged |
| Developed with | Claude Opus 4.8 (Claude Code) |
| License | MIT |
Intended use
A learning project — its purpose is to make the whole pipeline (data → training → checkpoint → sampling) legible and reproducible on a laptop. Good for understanding how a small GPT is trained and how character-level generation works. Generated text is stylistic mimicry, not coherent prose.
Out of scope: any real use of the text. The model has no knowledge, no factual grounding, and produces grammatically Shakespeare-flavored gibberish. Do not use it to generate content presented as Shakespeare or as fact.
Training data
Tiny Shakespeare — 1,115,394 characters (~40k lines, vocab 65), the classic
concatenation of Shakespeare's plays, via Karpathy's char-rnn. Split 90/10 into
~1.0M training / ~111k validation characters.
Training procedure
- Optimizer: AdamW, LR 1e-3 with cosine decay to 1e-4, 100 warmup iters, β₂ 0.99, batch size 64
- Run: 2000 iterations, dropout 0.2,
torch.compiledisabled (unreliable on macOS) - Hardware: Apple Silicon Mac (MPS / Metal backend), no NVIDIA GPU
- Wall-clock: ~16 minutes
Evaluation
Final validation loss 1.46 (train loss 1.08), down from 4.28 at initialization. The checkpoint is saved only when validation loss improves.
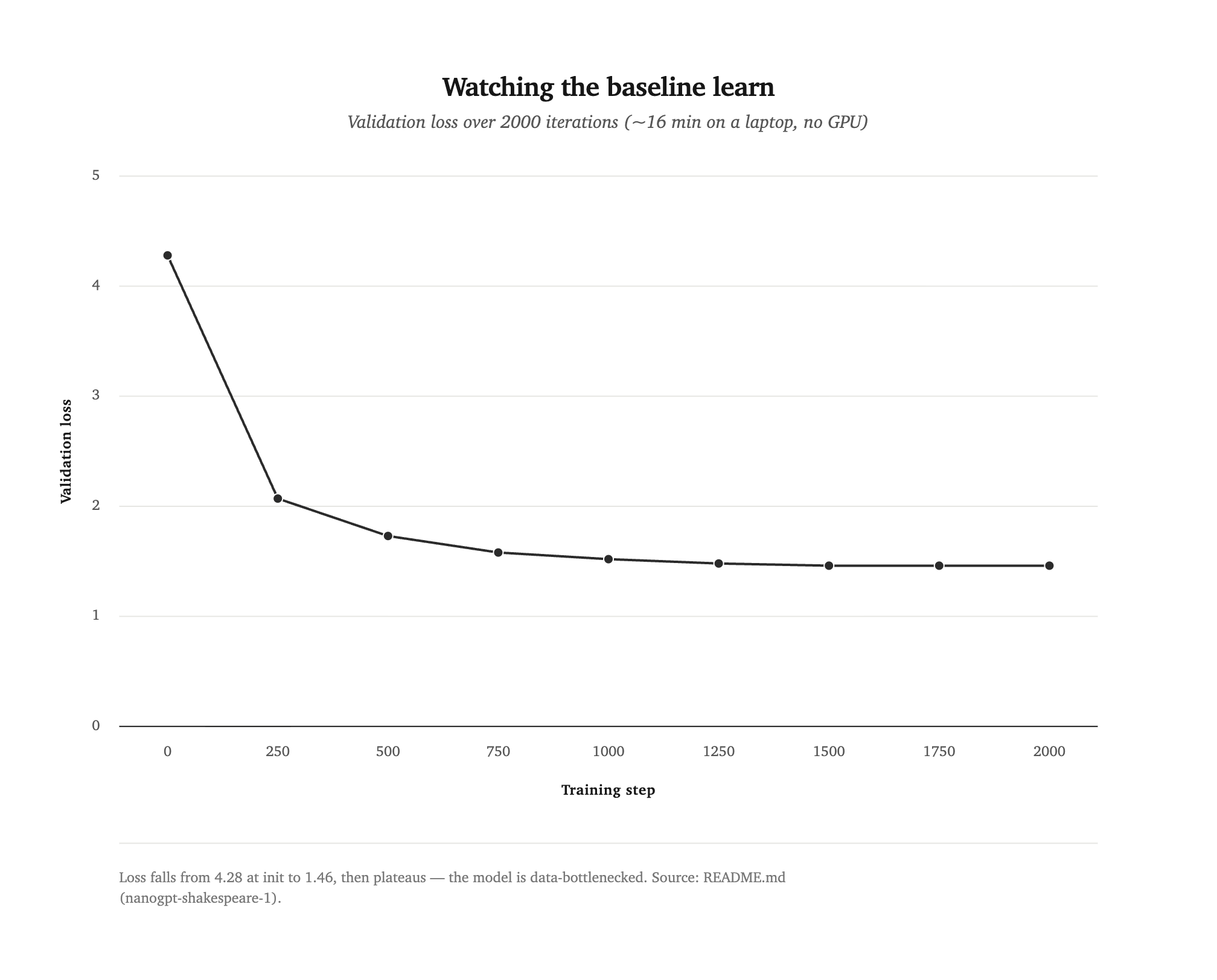
Loss falls steeply, then plateaus around 1.46 — the model is data-bottlenecked.
Chart generated by dataviz/.
Comparability. v1's headline figure (val 1.46 on Tiny Shakespeare's own split) is not directly comparable to v2's, which uses a different tokenizer and test set. The rigorous, tokenizer-agnostic metric is bits-per-character (BPC) on the fixed held-out test (
projects/shakespeare/test.txt); this data-starved char-level regime scores BPC 2.395 there, the controlled baseline the LLM-assisted research experiment improved on. See the v2 card.
Limitations
- Character-level + tiny corpus: learns spelling and rhythm, not meaning. Output is locally plausible, globally nonsense.
- Overfits / data-starved: ~1M characters is little data; this regime is the thing later versions fix with more data.
- No safety tuning, no instruction following, no factuality. It is a next-character predictor.
How to use
# self-contained v1 folder (weights are gitignored — rebuild them)
cd models/shakespeare-nanogpt-1
python prepare.py # downloads Tiny Shakespeare, builds the dataset here
python train.py # -> ./ckpt.pt
python sample.py --start="ROMEO:" --num_samples=1 --max_new_tokens=1000
Citation / credits
- nanoGPT by Andrej Karpathy (MIT) — model + training code.
- Tiny Shakespeare via Karpathy's
char-rnn. - Set up and trained with Claude Opus 4.8 (Claude Code).
Addendum — June 2026
Added in the site-standardization pass (ADR-0015). The card above is unchanged; this is a tracked addendum. Site-wide fixes — repo links now resolve to GitHub/site routes, code blocks render within the column — apply automatically.